Mastering Spark SQL Create Table: A Comprehensive Guide
Spark SQL is an essential component of Apache Spark, enabling powerful data processing and analysis through SQL queries. One of the foundational tasks in using Spark SQL effectively is creating tables that can store and manage data efficiently. Understanding how to utilize the Spark SQL create table command is crucial for developers and data engineers who aim to harness the full potential of big data applications. This article will delve into the intricacies of the Spark SQL create table command, providing insights on its syntax, options, and best practices. As we navigate through this topic, you will learn how to create tables effectively in Spark SQL, ensuring your data is well-organized and easily accessible.
In the world of big data, the ability to create and manage tables is vital. Spark SQL allows users to define a schema and store data in various formats such as Parquet, JSON, or even Hive tables. When you create a table in Spark SQL, you are essentially setting the stage for data manipulation and querying, which can lead to powerful analytics and reporting capabilities. This guide aims to walk you through the process of creating tables in Spark SQL, ensuring you have a solid understanding of its features and functionalities.
By the end of this article, you will have a clear understanding of how to use the Spark SQL create table command and be able to apply it in your own projects. Whether you are a beginner looking to get started with Spark SQL or an experienced developer seeking to refine your skills, this comprehensive guide will equip you with the knowledge needed to create tables effectively in Spark SQL. Let’s dive into the details!
Read also:How To Make Stickers A Comprehensive Guide
What is Spark SQL and Why is it Important?
Spark SQL is a component of Apache Spark that integrates relational data processing with Spark's functional programming capabilities. It allows users to run SQL queries on structured data, making it easier to work with big data in a familiar SQL syntax. The importance of Spark SQL lies in its ability to connect to various data sources, perform complex queries, and provide a unified data processing experience.
How Does Spark SQL Create Table Work?
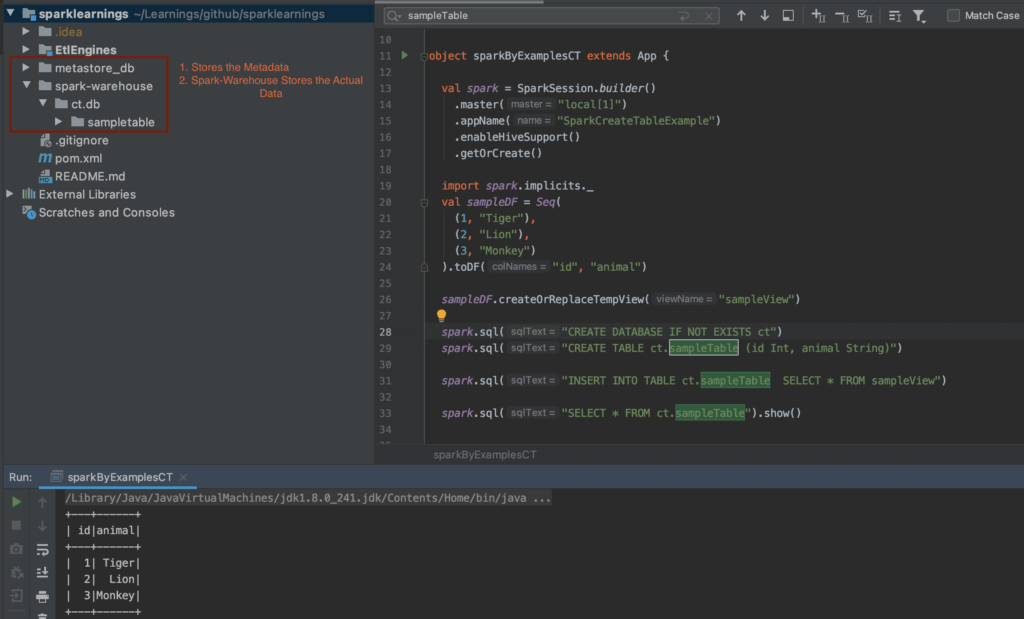
The Spark SQL create table command is used to create tables in a Spark SQL context. Users can define the table structure, including the data types and storage format. The command supports various options, such as partitioning and bucketing, which can improve query performance and data management. Understanding how to effectively use the create table command is essential for optimizing your data processing workflow.
What Are the Different Syntaxes for Spark SQL Create Table?
There are several syntaxes available for the Spark SQL create table command. Here are the most common ones:
- Create Table with a Schema: This syntax allows you to define the table structure explicitly.
- Create Table Like: This syntax creates a new table that has the same schema as an existing table.
- External Table Creation: This syntax is used to create tables that point to external data sources.
- Managed vs Unmanaged Tables: Understanding the difference between these types of tables is crucial for data management.
What Are the Steps to Create a Table in Spark SQL?
Creating a table in Spark SQL involves several steps. Here’s a simplified process to guide you:
- Open your Spark SQL environment.
- Decide on the table structure and data types.
- Choose the appropriate syntax for the create table command.
- Execute the create table command.
- Verify the table creation by querying the catalog.
What Are the Best Practices for Using Spark SQL Create Table?
To maximize the efficiency and performance of your data tables, consider the following best practices:
- Define clear schemas for your tables to avoid ambiguity.
- Use partitioning to improve query performance.
- Leverage bucketing for large datasets to enhance performance.
- Regularly monitor and optimize your tables to ensure they meet your data processing needs.
How to Handle Errors When Creating Tables in Spark SQL?
When working with Spark SQL, you may encounter errors while creating tables. Common issues include:
Read also:The Intriguing World Of Mc Meaning Unraveling The Mystery
- Schema Mismatch: Ensure that your data types match the defined schema.
- Storage Format Issues: Verify that the specified storage format is supported.
- Permission Denied: Check your access rights to the data source.
Can You Modify a Table After Creating It in Spark SQL?
Yes, you can modify a table after it has been created. Spark SQL provides various commands to alter tables, such as adding new columns, changing data types, or even dropping columns. The ability to modify tables is essential for adapting to evolving data processing requirements.
Conclusion: Mastering Spark SQL Create Table
In conclusion, mastering the Spark SQL create table command is essential for anyone working with big data. By understanding the various syntaxes, best practices, and potential pitfalls, you can effectively create and manage tables that enhance your data processing capabilities. Whether you are building new data pipelines or optimizing existing tables, the knowledge gained from this guide will serve you well in your Spark SQL endeavors.
Article Recommendations