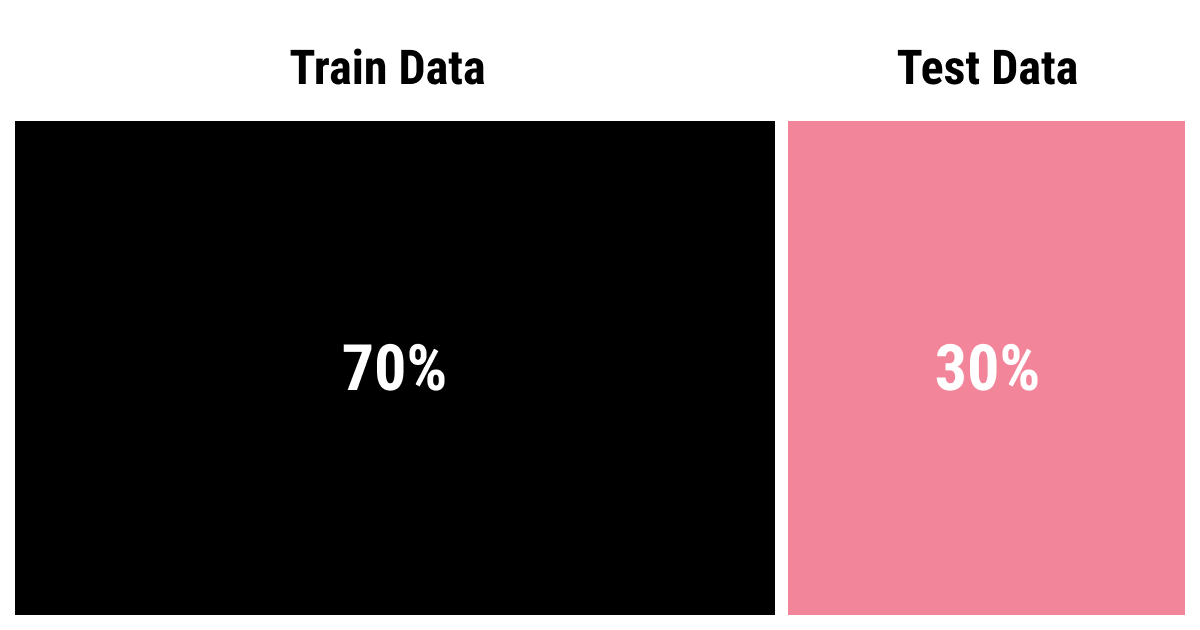
Mastering The 70 Training 30 Test Methodology: Unlocking Success In Machine Learning
When it comes to developing robust machine learning models, the methodology you choose can significantly impact your success. One of the most widely accepted approaches is the "70 training 30 test" paradigm. This technique is designed to maximize the effectiveness of your model by dividing your dataset into two distinct parts: a training set and a testing set. By allocating 70% of your data for training and reserving 30% for testing, you can create a balanced and effective framework that helps ensure your model is both accurate and reliable.
In the world of data science, the ability to train a model effectively while mitigating overfitting is essential. The "70 training 30 test" methodology allows data scientists to train their algorithms on a substantial amount of data while still retaining a sufficient amount for evaluation. This balance is crucial to understanding how well your model will perform on unseen data, which ultimately determines its real-world applicability. As we dive deeper into this article, we'll explore the various nuances of this methodology, its applications, and why it remains a popular choice among practitioners.
Whether you are a seasoned data scientist or a novice eager to learn the ropes, understanding the "70 training 30 test" approach is critical. This article will dissect the methodology, provide valuable insights, and equip you with the knowledge necessary to implement it effectively. Join us as we explore this pivotal aspect of machine learning and uncover the secrets to crafting models that excel in their performance.
Read also:Understanding The 86 Country Code A Comprehensive Guide With Fascinating Insights
What is the 70 Training 30 Test Methodology?
The "70 training 30 test" methodology is essentially a strategy for splitting your dataset into two parts: a training set and a testing set. The training set contains 70% of the data, which is used to teach the model how to recognize patterns and make predictions. The testing set, making up the remaining 30%, is then utilized to evaluate the model's performance on data it has never encountered before.
Why is Data Splitting Important?
Data splitting is crucial for several reasons:
- It helps to prevent overfitting, where the model performs well on training data but poorly on unseen data.
- It allows for a more accurate assessment of the model's predictive capabilities.
- The model can be fine-tuned based on feedback from testing results, improving its overall effectiveness.
How is the 70 Training 30 Test Split Implemented?
Implementing the "70 training 30 test" split is straightforward. Here’s a step-by-step guide:
- Collect your dataset and ensure it is clean and well-prepared.
- Randomly shuffle the data to ensure that the split is unbiased.
- Divide the dataset into two parts: allocate 70% for training and 30% for testing.
- Train your model using the training set.
- Evaluate the model using the testing set.
What Are the Advantages of the 70 Training 30 Test Approach?
There are numerous advantages to using the "70 training 30 test" approach:
- **Balanced Data Usage:** By using a significant portion of the data for training, you ensure that the model learns effectively.
- **Reliable Testing:** A dedicated testing set allows for an unbiased evaluation of the model's performance.
- **Flexibility:** This methodology can be applied to various types of data and models.
Are There Any Disadvantages to the 70 Training 30 Test Method?
While the "70 training 30 test" approach is beneficial, it does have some drawbacks:
- **Data Availability:** If you have a small dataset, allocating 30% for testing may result in insufficient data for evaluation.
- **Variability:** The results may vary depending on how the data is split, leading to different outcomes in model performance.
How Can You Optimize the 70 Training 30 Test Method?
To optimize the "70 training 30 test" methodology, consider the following tips:
Read also:Exploring The Captivating Traits Of Ravenclaw Unveiling The Wisdom And Wit
- **Cross-Validation:** Implement k-fold cross-validation to get a more reliable estimate of model performance.
- **Stratified Sampling:** Ensure that the training and testing sets maintain the same distribution of target classes, especially in classification tasks.
- **Use Larger Datasets:** If possible, increase the size of your dataset to improve the model's robustness.
What Kind of Models Benefit from the 70 Training 30 Test Method?
Many machine learning models can benefit from the "70 training 30 test" methodology, including:
- **Regression Models:** These models predict continuous outcomes and can be effectively trained and evaluated using this split.
- **Classification Models:** Models that categorize data into classes, such as logistic regression and decision trees, also benefit greatly.
- **Neural Networks:** These complex models require substantial training data to learn effectively.
Can the 70 Training 30 Test Methodology Be Used in Deep Learning?
Yes, the "70 training 30 test" approach is widely used in deep learning. However, given the vast amount of data required for training deep neural networks, practitioners often opt for variations such as:
- **80 training 20 test:** This allows for more training data while still keeping a portion for testing.
- **Holdout Validation:** In cases where data is plentiful, some data scientists may reserve a separate validation set as well.
How Does the 70 Training 30 Test Method Compare to Other Splitting Techniques?
When compared to other techniques like 80/20 or 60/40 splits, the "70 training 30 test" approach strikes a balance between training and testing data. It offers enough training data to learn effectively while still providing a reliable testing set for evaluation:
- **80/20 Split:** More data for training, but less for testing, which could lead to overfitting.
- **60/40 Split:** More testing data, but less training data may not allow for sufficient learning.
Conclusion: Embracing the 70 Training 30 Test Method
In conclusion, the "70 training 30 test" methodology is a foundational practice in machine learning that offers a straightforward yet effective way to train and evaluate models. By understanding the principles behind this approach, you can enhance your data science skills and create models that perform well in real-world scenarios. As you embark on your journey in machine learning, remember that the key to success lies not just in the algorithms you choose, but also in how you prepare and evaluate your data.
Article Recommendations
![Train Test Validation Split How To & Best Practices [2022] (2022)](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/61568656a13218cdde7f6166_training-data-validation-test.png)